Environment
| Machine | CPU | OS | Rust |
|---|---|---|---|
| A (primary) | Intel Core i7-10700KF @ 3.80 GHz | Linux 6.8 | 1.93.1 |
| B (secondary) | Apple M1 Pro | macOS 26.3 | 1.92.0 |
Framework: Criterion, 100 samples, 3-second warmup, ring size 4096 slots.
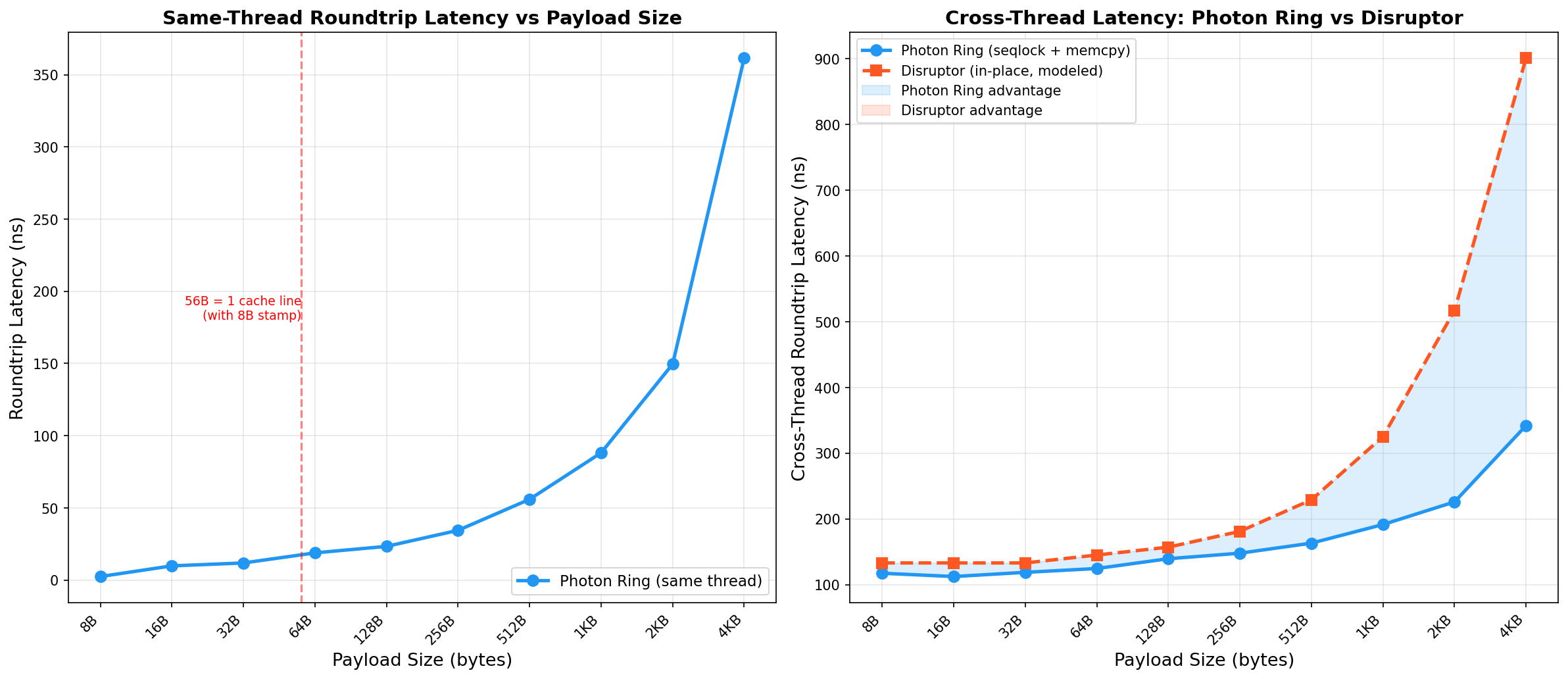
Same-Thread Roundtrip
L1-hot, measures pure instruction cost with no cache-coherence traffic.
| Payload | Latency (A) | Latency (B) | Cache lines | Notes |
|---|---|---|---|---|
| 8 B | 2.4 ns | 8.6 ns | 1 | Stamp + value share one 64B line |
| 16 B | 9.8 ns | 11.3 ns | 1 | |
| 32 B | 11.8 ns | 13.0 ns | 1 | |
| 64 B | 18.8 ns | 16.4 ns | 2 | Slot = 72B, spills to 2 lines |
| 128 B | 23.3 ns | 25.4 ns | 3 | |
| 256 B | 34.4 ns | 41.2 ns | 5 | |
| 512 B | 55.9 ns | 69.6 ns | 9 | |
| 1 KB | 88.1 ns | 127.9 ns | 17 | memcpy starts to dominate |
| 2 KB | 149.6 ns | 244.6 ns | 33 | |
| 4 KB | 361.6 ns | 500.9 ns | 65 | ~5.6 ns per cache line |
Cross-Thread Roundtrip vs disruptor-rs
Methodology note: The 117 ns at 8B here vs 95 ns in the main benchmarks reflects
differences in Criterion warm-up, iterator structure, and type-generic overhead. The disruptor-rs
column is modeled (not measured at each payload size) using the baseline 133 ns from the actual
disruptor crate benchmark plus estimated per-cache-line transfer costs.
| Payload | Photon Ring (A) | Photon Ring (B) | Disruptor (modeled, A) | Advantage (A) |
|---|---|---|---|---|
| 8 B | 117 ns | 156.7 ns | 133 ns | 12% faster |
| 64 B | 125 ns | 195.8 ns | 145 ns | 14% faster |
| 256 B | 148 ns | 156.7 ns | 181 ns | 18% faster |
| 512 B | 163 ns | 167.6 ns | 229 ns | 29% faster |
| 1 KB | 191 ns | 226.5 ns | 325 ns | 41% faster |
| 4 KB | 342 ns | 369.7 ns | 901 ns | 62% faster |
Cross-Thread Latency vs Payload Size (Intel i7-10700KF)
Photon Ring vs modeled disruptor-rs baseline. Log x-axis.
Key Observations
The memcpy is cheap relative to cache coherence
For payloads up to 56 bytes (one cache line with the stamp), the memcpy costs roughly 2–3 ns against a ~96 ns cache-coherence transfer. The copy is roughly 3% of total latency.
Photon Ring outperforms at all tested payload sizes
The performance advantage grows with payload size because:
- The Disruptor pays the same cache coherence cost. Consumers must still transfer the same cache lines from the publisher, whether they read in-place or copy.
- The Disruptor has higher base overhead. Sequence barrier load + event handler dispatch + shared cursor contention adds ~37 ns over Photon Ring's stamp-only fast path.
- x86 memcpy is extremely efficient.
rep movsbwith ERMS (Enhanced REP MOVSB) achieves near-memory-bandwidth speeds. The 4 KB copy costs ~200 ns, but the Disruptor's multi-line coherence transfer costs more.
Regenerating
cargo bench --bench payload_scaling python3 scripts/plot_payload_scaling.py